Markup Rant
Sat Oct 10 '20
What’s a Markup?
Markup languages let you annotate text files with other text that kind of looks like something a normal person can read or would write. But those annotations have special meaning to programs when they read the document and turn it into another format like HTML.
Each of the following two examples of markup might produce the heading (and the first few words) for the next section of this post.
In reStructuredText:
Markup ------ Years ago, blah blah blah ...In Markdown:
## Markup Years ago, blah blah blah ...
Who cares about markup?
Years ago, I started familiarizing myself with reST and have been using it ever since. I picked that over Markdown for a few reasons including:
Markdown’s lack of support for basic markup elements, like tables or footnotes.
Here’s some reStructuredText:
Wow. Look at this auto-numbered footnote. [#]_ .. [#] This is the footnote text!reST’s comparatively richer set of features for basic content, like using a hyphen (
-) to denote unordered list items, or anonymous hyperlink targets.Read what Wikipedia has to say about `markup languages`__. __ https://wikipedia.org/wiki/Lightweight_markup_language
Since then, Markdown implementations have extended what they support, narrowing the gap between their markup features and those of reStructuredText implementations.
However, the recourse for extending the markup is different in somewhat interesting ways.
More Markup
As far as I can tell, if you want something in your document that isn’t supported by Markdown, your option is to write inline HTML (or use a preprocessor that generates the inline HTML).
This is how I’ve seen people write markup for subscript, superscript, <abbr>, <kbd>, <figure>, or <picture> elements in HTML that don’t seem to have their own markup in any Markdown implementations. This is a problem for me for a couple reasons.
Inline HTML is, in my opinion, ugly to write and painful to read.
I feel obligated to state that this is just my preference. But I’d bet most human people would find explicit
<p align="center">and rows of</br>tags, designed to affect some sort of layout or whitespace that only makes sense when rendered as HTML on GitHub, to be a detriment to the readability of the file as text.[1]Writability matters somewhat less if you use a preprocessor. But that’s like saying that Markdown doesn’t have this problem if you don’t write Markdown and just generate it from some other format.
Inline HTML can limit our ability to render our document to other file formats.
I can understand most people only caring about rendering to HTML. For me, I think it’d be really cool if I could serve my website over Gemini in the
text/geminiformat. This is possible by mapping a markup language’s document structure totext/geminidirectly and generate that along side HTML. But, to support inline HTML in Markdown, you’d need to convert HTML as well.Inline HTML can reduce portability to other websites.
Including specific HTML markup in a Markdown file often assumes stuff about how the page is arranged, particularly for sectioning or heading content. (This is something I’ll bring up again later – because I am petty and just can’t let it go.)
Docutils provides a Python API to extend the markup while still using reStructuredText syntax.
For this website, I’ve extended it so that :hl-purple:`purple highlight` & :hl-yellow:`yellow highlight` can be used to produce purple highlight & yellow highlight respectively. In HTML, those elements are just <span> elements with a special class that receives a highlight from my stylesheet. In this case, it does exactly what I want it to do and I don’t have to shit up my file format with some out-of-band syntax.
However…
… reStructuredText has pain points.
Poor support for nested inline markup.
You can’t nest inline content in order to combine any of: hyperlink, emphasis, bold, strikethrough, pre-formated/code, <small>, superscript, subscript, etc.
You can hack it by defining new inline roles that specify a combination of these things but that’s annoying.
Extending block stuff can be difficult.
To support swapping diagrams between light and dark mode, I have two custom directives for <picture> and <source> HTML elements. It’s about three dozen lines of Python to define the directives and render them to HTML. The source for my modifications are on sr.ht.
This lets me write:
.. picture:: foo.svg
:alt: This is some alt text!
.. source::
:srcset: foo-dark-mode.svg
:media: (prefers-color-scheme: dark)It’s not amazing; but it’s not terrible. If I’m being pedantic, this probably should use light-mode/dark-mode semantics and not be coupled to CSS/media queries.
One thing I appreciate in Markdown is that block content need not be indented, like when using the markup for pre-formatted text/code fence blocks.
Top-level content.
```
Block content without indentation.
```Much of the time, indentation is nice to have. But, recently, I wanted a <details> element but, for reasons, I didn’t want to indent all the content contained therein. In reStructuredText I’m not sure there’s a way to establish block content without indentation.
Using some kind of delimiter to start and end blocks like backticks or tildes is a neat way to do it. I think heredocs are pretty cool and something like that would maybe be pretty text friendly.
There are not many great implementations.
Notable implementations are:
Many of the other implementations I’ve found often only support a subset of reStructuredText.[2]
I assume that this is evidence that reStructuredText is more difficult to implement. It probably also has to do with it being a little less popular. On the other hand, the implementation language shouldn’t matter much of the time.
Typically, there is no need to extend the document model[3] in the way that I have. All you care about is giving your document to some program and getting some HTML out.
Sphinx is a notable exception where extensions exist for the purpose of improving the tool’s function as a documentation generator. With my website, extensions exist to do with my specific styling and layout. These specifics should apply to reStructuredText documents it handles generally.
This is the most/only important point of this post.
For example, the HTML writer uses <section> elements to enclose up sections of the document near headers. If my documents were rendered on some other website that didn’t use/care for <section> elements, then my document shouldn’t produce them. Likewise, if I were to include a document written by someone else or for some other thing, I’d want it to be rendered with <section>. Having the document itself specify those structural HTML elements reduces portability and would be a mistake.
Not to just shit on the website that I clearly appreciate enough to copy to make froghat.ca, but lawler.io does this in their Markdown documents. They specify footnotes and sections (and a couple of other things) as HTML in their file. Not only does this reduce portability to document formats other than HTML, but it reduces portability to other websites that might structure or style HTML content differently.
Having a proper extensible document model is a huge win for reStructuredText for these reasons. It’s a big part of why I continue to use it in spite of the quirks I’ve mentioned so far.
CommonMark? more like CommonFart ha ha hhha ahha
At the time of writing, CommonMark’s most recent specification is 0.29.
I tried to look it over, but some of the links on the page didn’t work. It made me really upset. Now, I’m here, writing this, hoping the catharsis will allow me to move on with my life.
Briefly, here’s how links to elements on the same document are supposed to work.
<h2 id="interesting-topic">A Heading for an Interesting topic</h2>The element above is a second-level heading (that’s what h2 means) with an id attribute that is unique in that document.
Suppose that heading is on the page in your browser at froghat.ca/blag/markup-rant/. If you then visit froghat.ca/blag/markup-rant/#interesting-topic, your browser will scroll to that heading for you. It’s cool because you can link to specific parts of the page that way.
You can put a link on your page that does this so that when people click on the link it will go to the heading, or whatever element has the corresponding id. This is an example of the HTML for such a link:
<a href="#interesting-topic">Click here to read about an interesting topic!</a>Here’s an actual link that goes to the beginning of this section.
wooOOoOow you can link to things, ur so smart, gr8 job dood
Yah okay, internal hyperlinks are not super complicated.
So why does the page for CommonMark’s latest specification (archive.is link) contain the following paragraph:
<p>We can divide blocks into two types:
<a id="container-blocks" href="#container-blocks" class="definition">container blocks</a>,
which can contain other blocks, and <a id="leaf-blocks" href="#leaf-blocks" class="definition">leaf blocks</a>,
which cannot.</p>There are two links, each link to … themselves. Because each <a> element has the id that they target.
So when you click on those links in your web browser, you expect to go to the chapter talking about the topic. Instead, you just go to the paragraph that you’re already on.
There’s also a table of contents that links to the two chapters mentioned above, but now they target these links instead of the actual chapters.
Well what does the chapter look like?
<h1 id="container-blocks" href="#container-blocks" class="definition">
<span class="number">5</span>Container blocks
</h1>Okay, well at least the id attribute is set. But it’s supposed to be unique. If the link didn’t have this same id, it would probably navigate to the chapter like it’s supposed to. Also, this heading has an href attribute for some reason.
There are a lot of things great about this.
Links are not complicated to get right. You do the
hrefand theid.I don’t have a big brain for pointing this out. I’m just stroking my ego by drawing it along. (Probably from some deeply held self-resentment that externalizes as being overly-critical of other people’s stuff.)
This is clearly wrong through static analysis. The
idis supposed to be unique. And it’s not here.Run this on validator.w3.org (or use this archive.is link) and it will tell you as such.
This is clearly broken if you ever try to click on the links.
Bonus Meme Alert
The GitHub Flavored Markdown Spec, which appears derived from the CommonMark spec, has this problem as well.
Anyway …
I tried to understand Markdown because people suggest that it’s easy and simple and good. It’s not.
There are a bunch of different things that people mean when they talk about Markdown because of differences in what markup is supported across implementations. You want tables? You can’t use CommonMark, try GitHub Flavored Markdown. Want footnotes? See Markdown Extra/MultiMarkdown (or something) for that.
Or, you can have whatever you want by writing inline HTML (i.e. not Markdown) because fuck you.
Docutils and reStructuredText is complicated. I’m not overjoyed with it. The specification is large and, unfortunately, there are a lot of ways to use it that end up looking stupid. I wish this wasn’t the case. I wish it was straightforward and had more implementations and it was fun and it made you feel good when you used it.
In spite of that, it delivers and it has a specification that isn’t a stupid fucking busted document with broken links and a broken table of contents and that gets 50 errors and 7 warnings from the W3C Markup Validator. You know what would be an improvement over that?
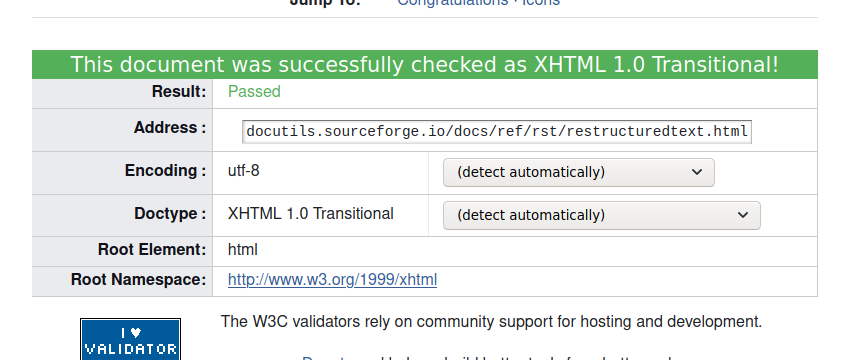
There are a things about Markdown that I appreciate or prefer. I can see it making a lot of sense for something like email or comments on reddit. Where LaTeX, for example, wouldn’t be most people’s first choice. And maybe that’s when Markdown peaked – when it just did those things. Now that it’s been extended, the tooling & ecosystem is worse.
JSON is a pretty bad file format. It’s hugely popular even though it lacks some basic types like dates or datetimes, has some dumb rules about commas, and looks stupid. For configuration files, where comments can be quite important, JSON gives you no help. YAML, is generally considered to be unnecessarily complicated and gets a lot of hate. So now TOML has gotten traction for filling a niche between the two (right on top of where INI used to be).[4]
Markdown and reStructuredText feel like JSON and YAML respectively. There are useful things in YAML, like tags, that aren’t replicated in any other of the popular option. Likewise, reStructuredText has some useful concepts that make it my preference a lot of the time. But it’s complicated and everyone hates it.
I just want Rich Hickey to come along and invent something nice and cozy in the middle that works for everything everywhere always so nobody will ever be sad ever again.